~今天要分享的是「KNN實作」~
理解了KNN的核心概念後來看看在Python中是如何撰寫程式碼來實作的吧~
KNN分析模型在sklearn的neighbors套件底下:from sklearn import neighbors
#使用在分類問題neighbors.KNeighborsClassifier()
#使用在迴歸問題neighbors.KNeighborsRegressor()
KNN在計算樣本間的距離時,可以選擇使用歐式距離法或曼哈頓距離法,在程式碼中可以透過KNN模型裡的參數”p”或”metric”來做設定。
歐式距離法:也稱為直線距離法,計算公式為√((X2-X1)^2+(Y2-Y1)^2),在KNN模型中可以將p設定為2或將metric設定為'minkowski'來使用歐式距離法。
曼哈頓距離法:也稱為城市街區距離法,計算公式為|X2-X1|+|Y2-Y1|,在KNN模型中可以將p設定為1或將metric設定為"manhattan"或"cityblock"來使用曼哈頓距離法。
[程式碼實作]
迴歸問題:使用sklearn的資料集”boston”進行分析,n_neighbors設定為3
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
boston_data=pd.DataFrame(boston['data'],columns=boston['feature_names'])
print("DATA:",boston_data.head())
print("=======================================")
boston_target=pd.DataFrame(boston['target'],columns=['target'])
print("TARGET:",boston_target.head())
print("=======================================")
X=boston_data[["CRIM",'ZN',"INDUS","CHAS","NOX","RM","AGE","DIS","RAD","TAX","PTRATIO","B","LSTAT"]]
y=boston_target['target']
from sklearn.model_selection import train_test_split
X_train, X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
from sklearn import neighbors
KNNR=neighbors.KNeighborsRegressor(n_neighbors=3,p=2)
KNNR.fit(X_train,y_train)
print("解釋力:",KNNR.score(X_test,y_test))
from sklearn.metrics import mean_squared_error
from math import sqrt
KNNR_pred =KNNR.predict(X_test)
rmse = sqrt(mean_squared_error(y_test, KNNR_pred))
print("rmse: %.3f" % rmse)
print("依變數平均值:",boston_target['target'].mean())
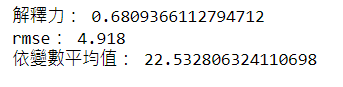
由結果可以得知,此模型的解釋力約為0.68,而目標變數裡的數據平均值約為22.53,模型誤差約為4.92,所以算是預測能力偏普通但可以參考的模型。
分類問題:使用sklearn的資料集”iris”進行分析,n_neighbors設定為5
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_data = pd.DataFrame(iris['data'],columns=iris['feature_names'])
print("DATA:",iris_data.head())
print("=======================================")
iris_target=pd.DataFrame(iris['target'],columns=['target'])
print("TARGET:",iris_target.head())
print("=======================================")
X=iris_data[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']]
y=iris_target['target']
from sklearn.model_selection import train_test_split
X_train, X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
from sklearn import neighbors
KNNC=neighbors.KNeighborsClassifier(n_neighbors=5,p=2)
KNNC.fit(X_train,y_train)
from sklearn.metrics import classification_report,confusion_matrix
KNNC_pred= KNNC.predict(X_test)
print("混淆矩陣:",confusion_matrix(y_test,KNNC_pred)))
print("======================================================\n")
print("模型驗證指標:",classification_report(y_test,KNNC_pred)))
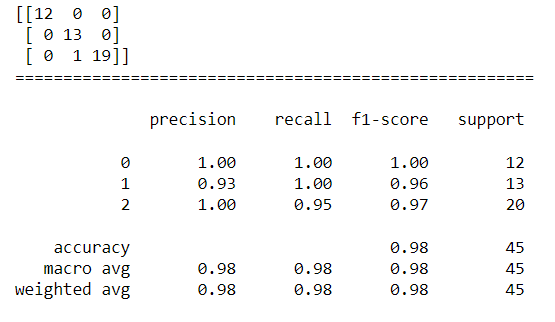
由結果可以得知,測試資料中有一筆分類為第1類的樣本被模型預測成第2類,因此出現了一點誤差,但整體正確率高達0.98,所以是一個蠻優秀的模型。


 iThome鐵人賽
iThome鐵人賽